你花了几万块换了最新模型,上下文窗口 168K,感觉稳了。
结果跑了半小时,Agent 开始乱来——幻觉增多、兜圈子、格式混乱,代码质量比刚开始差了一截。
你以为是模型变蠢了。
不是。是你的上下文窗口快满了。
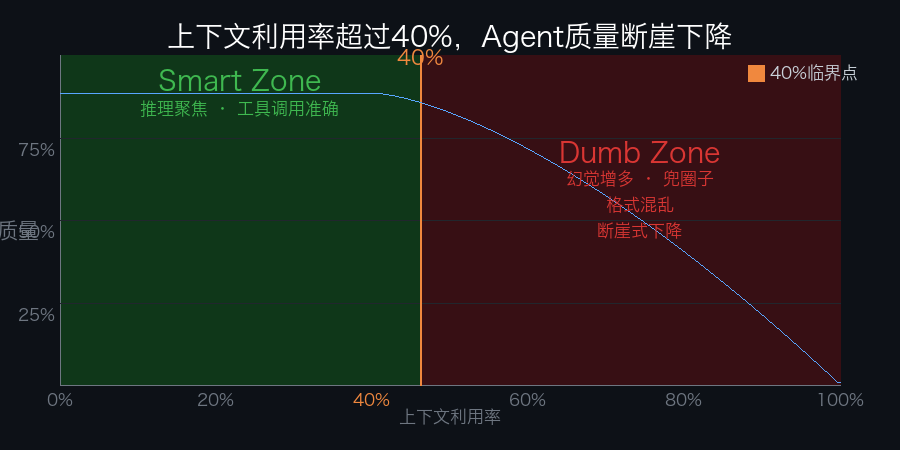
一个反直觉的数字:40%#
工程师 Dex Horthy 在观测 AI Agent 行为时发现了一个现象:
168K token 的上下文窗口,用到大约 40% 的时候,Agent 的输出质量就开始明显下降。
不是线性的,是断崖式的。
| 上下文利用率 | Agent 表现 |
|---|---|
| 0 – 40% | 推理聚焦、工具调用准确、代码质量高 |
| 超过 40% | 幻觉增多、兜圈子、格式混乱、低质量代码 |
Anthropic 也碰到了类似问题,他们内部叫”上下文焦虑”:Sonnet 4.5 在上下文快填满时会变得犹豫,倾向于提前收工——任务还没做完,它就开始”交卷”。
大多数人的第一反应是什么?换更大的上下文窗口。
没用。这个问题不是容量的问题,是信息管理的问题。
为什么换模型救不了你#
2025 年,有两个实验的结果让很多人重新审视自己的认知。
Can.ac 的工具调用实验 :同一个模型,只换了文件编辑接口的调用方式,编码基准分数从 6.7% 直接跳到 68.3%。模型没变,变的是外围的那套系统。
LangChain 的排行榜优化 :他们在 Terminal Bench 2.0 上从全球第 30 名升到第 5 名,得分从 52.8% 提升到 66.5%。换了模型吗?没有。只是优化了文档组织方式、验证回路和追踪系统。
这两个案例指向同一个结论:模型决定上限,Harness 决定底线。
你不是模型,那你就是 Harness。
Harness 是什么?模型之外的一切——系统提示词、工具调用、文件系统、沙箱环境、编排逻辑、约束机制、反馈回路。模型只是能力的来源,只有通过 Harness 把状态、工具、反馈和约束串起来,它才真正变成一个 Agent。
LangChain 的 Vivek Trivedi 打过一个比方:模型是 CPU,Harness 是操作系统。你买了最新款 M5 芯片,装了个天天崩溃的系统,体验还不如老芯片配稳定的 OS。
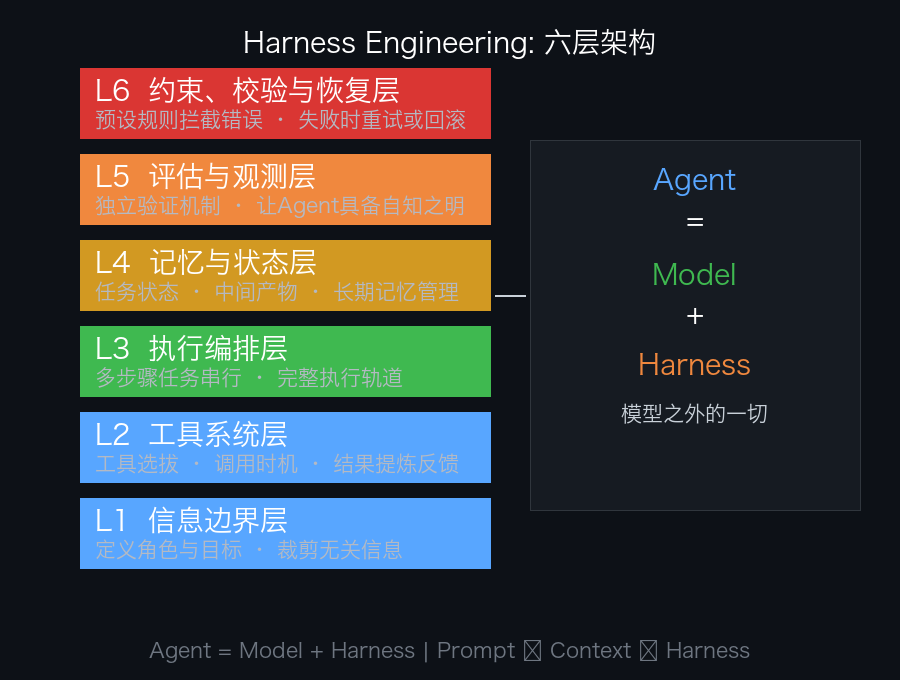
六层架构:把 Harness 拆开看#
一个成熟的 Harness 到底是什么样子?行业里有一个六层体系框架,把整个系统拆得很清楚:
| 层级 | 名称 | 解决什么问题 | 关键设计 |
|---|---|---|---|
| L1 | 信息边界层 | Agent 该知道什么、不该知道什么 | 定义角色与目标,裁剪无关信息,结构化组织任务状态 |
| L2 | 工具系统层 | Agent 怎么跟外部世界交互 | 工具的选拔、调用时机、结果的提炼与反馈 |
| L3 | 执行编排层 | 多步骤任务怎么串起来 | 让模型像人一样走完”理解目标→判断信息→分析→生成→检查”的完整轨道 |
| L4 | 记忆与状态层 | 长任务中间结果怎么管 | 独立管理当前任务状态、中间产物和长期记忆,防止系统混乱 |
| L5 | 评估与观测层 | Agent 怎么知道自己做对了没有 | 建立独立于生成过程的验证机制,让 Agent 具备”自知之明” |
| L6 | 约束、校验与恢复层 | 出错了怎么办 | 预设规则拦截错误,失败时提供重试或回滚机制 |
类比一下:给一个新手员工搭建完整工作环境。
- L1 是岗位说明书(告诉 ta 该关注什么)
- L2 是办公工具(给 ta 用什么干活)
- L3 是标准操作流程(按什么步骤做事)
- L4 是项目管理系统和笔记本(怎么记住做过的事)
- L5 是质检流程(怎么检验做对了没有)
- L6 是红线规则和应急预案(什么事绝对不能做、出了事怎么补救)
六层不是一次性全搭。从 L1 和 L6 入手,这两层投入产出比最高。L1 决定了 Agent 知道该干什么,L6 决定了它搞砸了能不能拉回来。中间层次随着项目复杂度增长逐步补齐。
一线团队怎么用这套框架#
Anthropic:用”重启”代替”压缩”#
上下文焦虑的问题,Anthropic 的解法很有意思——不是继续压缩上下文,而是直接重启 。
当 Agent 的上下文接近饱和时,先把当前任务状态、已完成的工作、待办事项结构化地提取出来,然后启动一个全新的”干净”Agent,把交接文档交给它,从干净的状态继续。
这就像程序碰到内存泄漏——不去手动释放每一个内存块,而是直接重启进程,从检查点恢复。虽然粗暴,但一个干净的 Agent 比一个塞满历史信息的 Agent 表现好得多。
这个思路后来被 Anthropic 团队进一步结构化,发展成了一个GAN 式三智能体架构 :
Planner(规划者) → Generator(执行者) ⇄ Evaluator(评估者)
- Planner 拿到产品描述后扩展成完整规格,被要求”在范围上要大胆”
- Generator 按功能一个一个做 Sprint,每个 Sprint 有明确的完成标准
- Evaluator 用 Playwright MCP 实际点击运行中的应用,按产品设计、功能性、视觉、代码质量打分
Evaluator 独立于 Generator——你不能让写代码的人同时检查自己写得对不对。他们还故意把前端设计质量和原创性的权重调得比功能性更高,因为模型天然倾向于做出”功能齐全但长相平庸”的东西。
OpenAI:约束不能写在文档里#
OpenAI 的三个工程师用 Codex 5 个月生成了 100 万行代码。他们的核心经验之一:
If it cannot be enforced mechanically, agents will deviate.
文档中记录约束是不够的;如果不能机械化地强制执行,Agent 就会偏离。
他们给每个业务领域定义了固定的分层结构:
Types → Config → Repo → Service → Runtime → UI
依赖方向不能反过来。怎么保证?自定义 Linter 加结构测试。违反了就报错,报错消息里不光告诉你哪里错了,还直接告诉你怎么改。Agent 在被纠错的同时就被”教会”了正确的做法。
另一个经验:AGENTS.md 不是一本千页手册,而是一张地图。OpenAI 的 AGENTS.md 只有大约 100 行,作用是目录,指向 docs/ 目录下更详细的文档。需要什么再加载什么,而不是一开始把所有东西都塞进去。
Mitchell Hashimoto:犯一次错,工程化一个解法#
Hashimoto(Vagrant、Terraform、Ghostty 的作者)走的是另一条路——他坚持一次只跑一个 Agent,保持深度参与,不跑多 Agent 并行。
他的六步路线很实用:
- 放弃聊天模式,让 Agent 在能读文件、跑程序的环境里直接干活
- 每件事做两次——一次自己做,一次让 Agent 做(他说”痛苦至极”但这是最快学习路径)
- 下班前 30 分钟启动 Agent 做调研、Issue 分拣
- 挑出 Agent 几乎一定能做好的确定性任务后台跑
- 每当 Agent 犯了一个新类型的错,就工程化一个解决方案让它永远不再犯
- 目标是 10-20% 的工作时间有后台 Agent 在跑
Ghostty 项目里的 AGENTS.md,每一行都对应着一个过去的 Agent 失败案例。这不是写完就扔的静态文档,是一个持续积累的防错系统。
Stripe:确定性流程和 Agent 流程的混合编排#
Stripe 的 Minions 系统走的是另一个极端——高度自动化的无人值守模式。开发者发一条 Slack 消息,Agent 从写代码到跑 CI 到提 PR 全部搞定,人只在最后审查。每周超过 1300 个完全由 Agent 生产的 PR 被合并。
他们没有把所有事情都交给 Agent 判断,而是设计了一个混合状态机:
- 确定性节点 :lint 检查、代码推送——这些必须走固定流程,不允许 Agent 自由发挥
- Agent 节点 :实现功能、修 CI 错误——这些需要灵活判断
该确定的地方确定,该灵活的地方灵活。像一条工厂流水线,有些工位是机器人固定动作,有些工位是人工灵活处理。
从零搭 Harness,从哪入手#
综合一线团队的实践经验,有一个按优先级的行动清单:
P0:立即可以做,效果立竿见影
- 创建 AGENTS.md 并持续维护。Agent 每次启动自动加载,犯错就更新,形成反馈循环。Hashimoto 的 AGENTS.md 每一行对应一个历史失败案例。
- 构建自定义 Linter + 修复指令。错误消息里直接告诉 Agent 怎么改,纠错的同时在”教”。
- 把团队知识放进仓库。写在 Slack 或 Wiki 里的知识对 Agent 等于不存在。OpenAI 以仓库为唯一事实源。
P1:P0 做完之后升级
- 分层管理上下文,不要把所有东西塞进一个文件,渐进式披露。OpenAI 的 AGENTS.md 当目录用(约 100 行),详细规则放在子文档中按需加载。
- 建立进度文件和功能列表,用 JSON 格式追踪功能状态。Agent 不太会乱改结构化数据。
- 控制上下文利用率,尽量不超过 40%。增量执行,不要等 Agent 变蠢了再处理。
P2:有余力再考虑
- Agent 专业化分工。每个 Agent 携带更少无关信息,留在 Smart Zone。
- 定期垃圾回收,确保清理速度跟得上生成速度。OpenAI 的后台清理 Agent 定期扫描文档不一致、架构违规和冗余代码,自动提交清理 PR。
- 可观测性集成,把”性能优化”从玄学变成可度量的工作。
一句话总结#
模型换到顶了还是拉胯,瓶颈大概率不在模型,在 Harness。
168K 上下文窗口,用到 40% 就开始变蠢。工具调用格式换一下,分数能从 6.7% 跳到 68.3%。这些都不是模型的锅,是系统设计的锅。
与其追最新的模型,不如先把六层架构搭好。 L1 定边界,L6 保底线,中间层按需补齐。模型决定上限,Harness 决定底线——这句话值得贴在每个 AI 工程团队的墙上。
你们团队搭 Harness 了吗?现在卡在哪一层?评论区聊聊。